*****
If intrigued by this idea of determining which parallel query thread thread at a given DOP a value or values will be assigned to by hash partitioning, please also see this post by Joe Obbish.
A Serial Parallel Query
https://orderbyselectnull.com/2017/09/26/a-serial-parallel-query/
*****
The SQL below will create a table with 2^(n-1) rows with num value n, for each integer n between 1 and 16. The total number of rows in the table is 2^15 - 1 or 65535.
This first draft code isn't elegant or very efficient. It took 8 minutes and 11 seconds to complete on the test vm. But a table with this structure should be very valuable in experiments to learn about hash distribution of rows among parallel threads. Originally I though it might also lead to leaning a bit about how the parallel page supplier works. (Not so much.)
DROP TABLE IF EXISTS lnieders_bitmap;
CREATE TABLE lnieders_bitmap(num INT, fluff VARCHAR(4100));
CREATE CLUSTERED INDEX ci__lnieders_bitmap ON lnieders_bitmap(num);
DECLARE @p2 INT = 16, @fluff VARCHAR(4100) = REPLICATE('Z', 4100);
;WITH nums_1 AS (SELECT TOP (POWER(2, @p2)-1) ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) rn
FROM master..spt_values t1 CROSS JOIN master..spt_values t2),
ctrl_cte AS (SELECT TOP (@p2) rn, SUM(POWER(2, rn - 1)) OVER(ORDER BY rn ROWS UNBOUNDED PRECEDING) rt FROM nums_1),
nums_2 AS (SELECT nums_1.rn, ctrl_cte.rn target_value FROM nums_1 LEFT OUTER JOIN ctrl_cte ON nums_1.rn = ctrl_cte.rt)
INSERT INTO lnieders_bitmap SELECT TOP(POWER(2, @p2)-1) cx.tv, @fluff FROM nums_2 t1
CROSS APPLY (SELECT MIN(target_value) tv FROM nums_2 t2 WHERE t2.rn >= t1.rn) cx ORDER BY t1.rn ASC;
SELECT COUNT(*) data_page__count
FROM sys.dm_db_database_page_allocations(db_id(), object_id('lnieders_bitmap'), 1, NULL, 'DETAILED')
WHERE page_type_desc = 'DATA_PAGE';
Joe Obbish read my code above and had some comments:
- that code is so confusing to read
- if change it like so it'll finish in 2 seconds
- still not the way I'd probably do it if starting from scratch
Thanks, Joe!! Sure enough, I modified the code according to his suggestions and 65535 rows were created in 2 seconds. So I increased the expected total number of rows from 65535 to 131071 which is where I wanted to be anyway. That took four seconds. To create 131071 rows with my original code would have taken... a *lot* longer. 😁
After Joe's help the code looked like this.
DROP TABLE IF EXISTS #t;
DECLARE @p2 INT = 17;
WITH nums_1 AS (
SELECT TOP (POWER(2, @p2)-1) ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) rn
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
)
, ctrl_cte AS (
SELECT rn
, SUM(POWER(2, rn - 1)) OVER (ORDER BY rn ROWS UNBOUNDED PRECEDING) rt
FROM nums_1
WHERE rn <= @p2
)
, nums_2 AS (
SELECT nums_1.rn, ctrl_cte.rn target_value
FROM nums_1
LEFT OUTER JOIN ctrl_cte ON nums_1.rn = ctrl_cte.rt
)
SELECT * INTO #t
FROM nums_2
OPTION (RECOMPILE);
DROP TABLE IF EXISTS lnieders_bitmap;
CREATE TABLE lnieders_bitmap(num INT, fluff VARCHAR(4101));
CREATE CLUSTERED INDEX ci__lnieders_bitmap ON lnieders_bitmap(num);
DECLARE @fluff VARCHAR(4101) = REPLICATE('Z', 4101);
INSERT INTO lnieders_bitmap WITH (TABLOCK)
SELECT MIN(target_value) OVER (ORDER BY rn DESC ROWS UNBOUNDED PRECEDING), @fluff
FROM #t t1
OPTION (RECOMPILE);
Much faster, much nicer. So here's the idea: since each integer value
n 1 to 17 is represented in the table with 2^
n rows, when rows are distributed to parallel threads by hash the number of rows for the thread will tell me
which values went to each thread, too.
Will this also allow me to make observations about the parallel page supplier? The threads of a parallel scan get their page sets from the parallel page supplier... but there's not much info beyond that publicly available
*****
Later on I thought "hey, I'll save myself some thought if I do this in base 10 rather than base 2." I also wanted to see how Joe Obbish would have approached creating this type of table from scratch. I asked, and he taught me a new trick (which I'll likely have to keep coming back to here otherwise I won't remember how it worked).
This isn't exactly how Joe did it, but its as close as I get from memory.
This query shows how it works.
;WITH base(base) AS (SELECT 10),
pwr(pwr_plus1) AS (SELECT 6),
nums_1(num_1) AS (SELECT ROW_NUMBER() OVER(ORDER BY(SELECT NULL))
FROM master..spt_values t1 CROSS JOIN master..spt_values t2),
nums_2(num_2, tv) AS (SELECT num_1, POWER(base, num_1-1)
FROM nums_1 cross join pwr cross join base WHERE num_1 <= pwr.pwr_plus1),
nums_3(num_3) AS (SELECT num_2 FROM nums_1 JOIN nums_2 ON nums_1.num_1 <= nums_2.tv)
SELECT num_3 val, COUNT(*) num_rows_at_val FROM nums_3 GROUP BY num_3 ORDER BY num_3;
So here's how it comes together to make my table for exploring.
DROP TABLE IF EXISTS b10_bitmap;
CREATE TABLE b10_bitmap(ID BIGINT INDEX pk_b10_bitmap CLUSTERED, FLUFF VARCHAR(4100));
;WITH base(base) AS (SELECT 10),
pwr(pwr_plus1) AS (SELECT 6),
nums_1(num_1) AS (SELECT ROW_NUMBER() OVER(ORDER BY(SELECT NULL))
FROM master..spt_values t1 CROSS JOIN master..spt_values t2),
nums_2(num_2, tv) AS (SELECT num_1, POWER(base, num_1-1)
FROM nums_1 cross join pwr cross join base WHERE num_1 <= pwr.pwr_plus1),
nums_3(num_3) AS (SELECT num_2 FROM nums_1 JOIN nums_2 ON nums_1.num_1 <= nums_2.tv),
fluff(fluff) AS (SELECT REPLICATE('Z', 4100))
INSERT INTO b10_bitmap SELECT num_3 val, fluff FROM nums_3 CROSS JOIN fluff ORDER BY num_3;
UPDATE STATISTICS b10_bitmap(pk_b10_bitmap) WITH FULLSCAN;
That created 111111 rows in 47 seconds. Let's check up on it... how many data pages?
111,111 data pages - good.
OK, now let's have some fun.
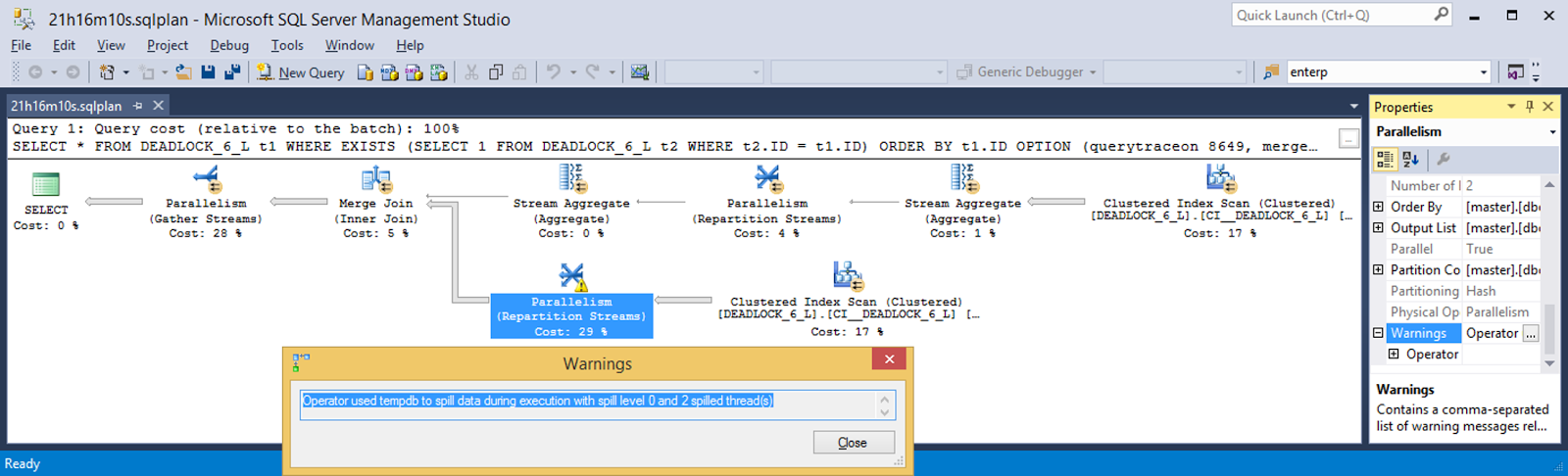
Let's take a look at the spread of rows/pages in that top right clustered index scan. Thread 1 with 55366 rows and thread 2 with 55745. That's a pretty even split of work between the threads. That's what we want out of the storage engine scan - split the work fairly evenly among worker threads.
What about the clustered index scan right below it? That's about a 90-10 split. The storage engine parallel page supplier isn't dividing pages up for the threads based on values in the clustered index - neither of the splits show the kind of numbers needed for the distribution to align with my crafty set of data. Figuring out how the parallel page supplier is coming up with sets of pages will take more investigation than this post can afford - since it'll require at least one separate investigation method. I'll have to explore the parallel page supplier more at another time.
On to a peek at how rows are being distributed among parallel threads by a hash function. The Repartition Streams operator details indicates using a hash to distribute the rows. Thread 1 handled almost 100 times as many rows as thread 2. Based on the number of rows of this table each thread handled, we can tell that thread 1 handled the rows with values 5 and 6 while thread 2 handled rows with values 1, 2, 3, and 4.
Here's what distribution of rows looked like at that operator for each DOP from 2 to 6. I'm intrigued, to say the least. Especially interesting to me is that DOP 5 and DOP 6 each had only 4 threads active. But the 4 active threads had different values going to them at DOP 5 and DOP 6.
All right. The role of the fluff was to help explore the parallel page supplier. I won't get anywhere with that tonight, so let's cut the fluff. GTFOH - Get the fluff out of here! 😁 And let's go back to base 2 - it'll allow me to work more values into a given number of rows. Might as well page compress them, too. This got me 262143 rows in 30 seconds.
CREATE TABLE b2_bitmap(ID BIGINT INDEX pk_b2_bitmap CLUSTERED)
WITH (data_compression = page);
;WITH base(base) AS (SELECT 2),
pwr(pwr_plus1) AS (SELECT 18),
nums_1(num_1) AS (SELECT ROW_NUMBER() OVER(ORDER BY(SELECT NULL))
FROM master..spt_values t1 CROSS JOIN master..spt_values t2),
nums_2(num_2, tv) AS (SELECT num_1, POWER(base, num_1-1)
FROM nums_1 cross join pwr cross join base WHERE num_1 <= pwr.pwr_plus1),
nums_3(num_3) AS (SELECT num_2 FROM nums_1 JOIN nums_2 ON nums_1.num_1 <= nums_2.tv)
INSERT INTO b2_bitmap SELECT num_3 val FROM nums_3 ORDER BY num_3;
UPDATE STATISTICS b2_bitmap(pk_b2_bitmap) WITH FULLSCAN;
Pretty tiny table, though. There's room for more - this can only get more interesting with more values in the table. But, I'll stick with this for now.
Here's the query I'm using. In this case, I'll look at DOP 3 to DOP 12. At DOP 2, the Repartition Streams operator highlighted before isn't present. So for now, just look at DOP 3 to DOP 12.
For DOP 3 to DOP 7...
And for DOP 8 to DOP 12...
Ciao for now!