*** This post was updated 2020 October 10 with some additional details at the end. ***
Today was kind of a rough day. It started with a colleague asking if I knew any handy tricks that could magically make dozens of queries go back to the seconds or minutes they ran at under SQL Server 2012 rather than the increments of half-hours they were taking since an upgrade to SQL Server 2016.
Well - I know a few. Was trace flag 4199 globally enabled on 2012? Yep. And on 2016? Database Compat level 2016, and optimizer hotfixes enabled in database scoped configuration.
Ok. Well, in SQL Server 2012 they were using the Legacy CE because it was the only one around. How about on SQL Server 2016? Legacy CE enabled in database scoped configuration.
Oh.
How about ascending key? Trace flag 4139 was globally enabled in SQL Server 2012. And in SQL Server 2016? Yep, globally enabled there, too.
Trace flag 4138 to disable row goal adjustments has sometimes made a huge difference. I didn't mention it yet, though. Better to see an affected plan first. And once I saw an affected plan... well, it really didn't look like trace flag 4138 could help, either. The bad plan was all nested loop joins, filters, parallelism operators and compute scalar operators. By adding a HASH JOIN hint, the plan looked more familiar to my colleague and query performance went back to the few seconds normally expected. But the developers wanted to understand the regression, and if possible avoid adding the hint to dozens or maybe even more than a hundred queries.
That was just about the end of my quick-n-easy list. For good measure my colleague checked what happened to the plan with SQL Server 2012 compat level: no substantive change. And with the default CE: no substantive change.
I started staring at statistics. Maybe some very important, very popular stats had fallen prey to extremely unlucky samples.
I became very suspicious when I noticed that a fairly important auto-created statistics object was on a varchar(66) column. But the query used integer values for that column heavily in the query predicate.
Sure 'nuf, the range_high_values were all integers, but because the column was varchar, the range_high_keys were dictionary sorted. That always makes me kinda suspicious.
And in that original query plan, a three million row table was pushed through a filter with a row estimate of 1 coming out. That's very suspicious.
So for several hours I tested various hinky ideas.
And finally, late on a Friday night, I think I discovered the problem. I won't know for sure until Monday when similar tests can be run on-site against their data on a SQL Server 2016 and 2012 system. But... even if this isn't *that* problem, it is *a* problem and its present in SQL Server 2019 CU6.
Time for show and tell. This work is being done in SQL server 2019 CU6.
Let's create a simple 3 column table. Each of the columns are varchar data type. Create statistics on col1. Populate the table with 50,000 rows. The first column col1 gets populated with integers from 9900 to 14900, in multiples of 100. Then let's update statistics.
CREATE TABLE [dbo].[stats_test4](
[col1] [varchar](66) NOT NULL,
[fluff] [varchar](4200) NULL,
[col2] [varchar](66) NOT NULL
) ON [PRIMARY];
CREATE STATISTICS stats_test4__col1 ON stats_test4(col1);
;with nums as
(select top (1000) n = row_number() over (order by (select null))
from master..spt_values)
, recur as
(select top (50) n = row_number() over (order by (select null))
from master..spt_values)
, fluff as
(select z = replicate('Z', 4100))
insert into stats_test4
select 10000 + 100 * (nums.n % 50 - 1), fluff.z, 1
from nums
cross join recur
cross join fluff;
UPDATE STATISTICS stats_test4(stats_test4__col1);
Here's what the statistics look like... there are 47 steps and only 26 of them are in the picture below... but the last 21 are boring anyway.
Let's generate an estimated plan for a query with an IN list in the WHERE clause. These two examples are with the legacy cardinality estimator. There are 19 integer members of that IN list. You can see the implicit conversion warning on the SELECT operator below. Column col1 is varchar(66), but it is being evaluated against a list of integer values. That filter operator is where the relevant action is right now. An estimate of almost 16000 rows is fine by me.
But the world is not enough. Nineteen integers? How about 20?
With 20 integers in the IN list, the estimate at the filter drops from nearly 16000 to... 1.
The downstream effects can easily be that desired hash joins become loop joins due to low row estimates.
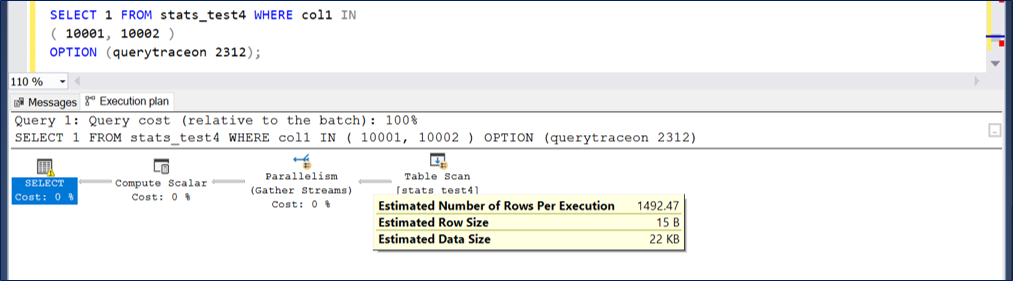
Now let's see what happens with default cardinality estimator. Let's start with a single integer IN list.
An estimate of 1000.
And with two integers in the IN list the estimate is at 1492.47.
The decreasing rate of growth is the work of exponential backoff...
With three integers in the IN list the exponential backoff is even more evident...
Here's 4 integers...
At 5 integers in the IN list, the estimate of 1858.58 hasn't grown from the previous estimate. From here on out the estimate won't grow.
Certainly there are other details surrounding this issue. I'll be back to fill in more as I learn more. In particular on Monday I should be able to transplant what I've learned in SQL Server 2019 to some on-site 2012 and 2016 databases. That should conclusively indicate whether this is part of the current bad stew... or something I should remember for the future when I run into it again.
*** Update 2020 October 10 ***
With additional testing, we learned that in SQL Server 2012 RTM this behavior did not occur: we tested up to 40 elements in the IN list and the estimate did not yet drop to 1.
I don't expect Microsoft to continue *enhancing* the legacy cardinality estimator. This could be considered a performance regression, and if the organization were interested they could push for a change. I'd expect, even if they were successful, the change to likely only appear in SQL Server 2019. They've decided rather to change their code where applicable so that literal values in OR clauses or IN lists are provided in matching data type to the relevant column, avoiding the implicit conversion and also avoiding this potentially disastrous performance implication after the cliff at 19/20 elements.