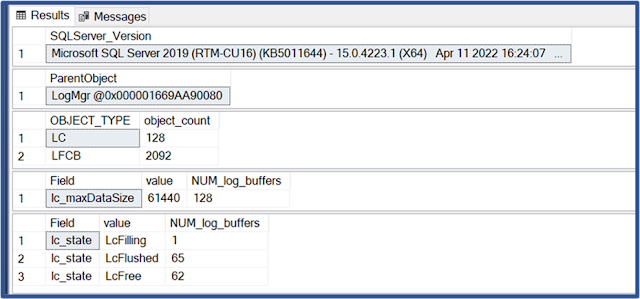
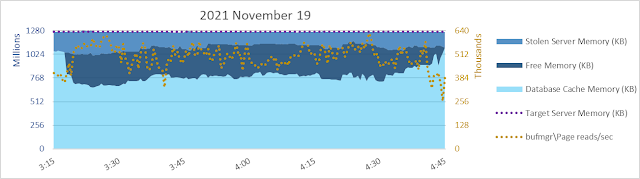
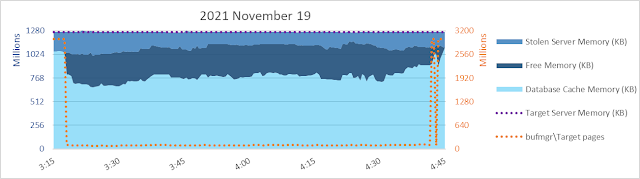
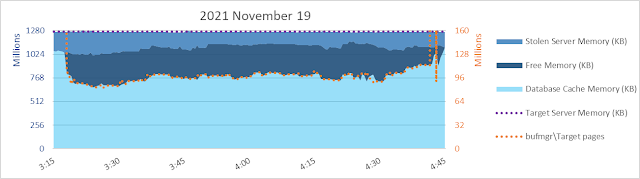
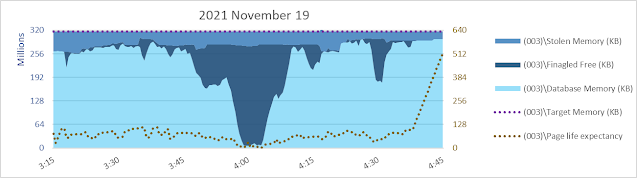
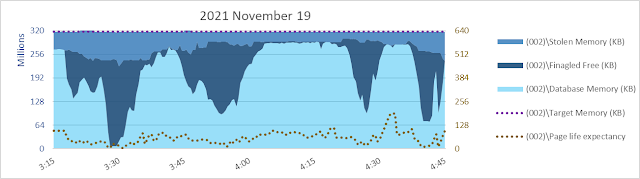
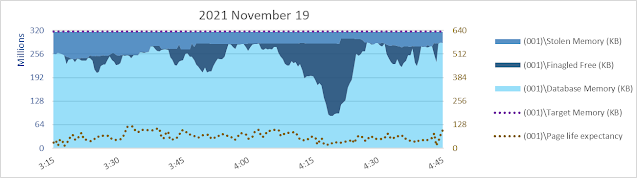
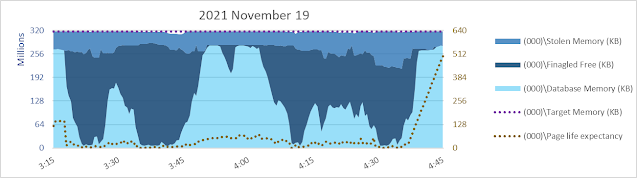
Today (2023 March 10) I am having memories of helping with bcp from one SQL Server 2008 R2 database to another of a 9.5 billion+ row table back in 2013. Yikes. bcp out - no need to think about uniqueifiers and error 666.
bcp in of 9.5 billion rows to a table with a clustered index and some NCIs on the other hand...
SELECT text FROM sys.messages WHERE message_id = 666 and language_id=1033
The maximum system-generated unique value for a duplicate group was exceeded for index with partition ID %I64d. Dropping and re-creating the index may resolve this; otherwise, use another clustering key.SQL 2005 kb 937533 is relevant. Table spool may only be able to handle 2,147,483,648 input rows before exhausting the available values for uniqueifier.
Here's a SQL Server 2008 example from the wayback machine.
First posted 2010 March 8
General considerations around uniqueifier and error 666 here.
2018 February 16
Now i *think* if the -b parameter for bcp specifies a batch size (maybe 100,000 or a million in this case) for an humongous import it will:
- lower the liability for transaction log full that accompanies simple recovery model, ADR not enabled in SQL Server 2019 and beyond, and a clustered index which is non-empty to start with
- lower the maximum footprint of spool or spill in tempdb for sort before clustered index insert- avoid potential uniqueifier 666 errors
Once i get the most recent trouble with big-big table migration sorted out, i'll work on a repro of the problem.