i was really glad to read this paper from the folks at VMware.
SQL Server VM Performance with VMware vSphere 6.5
https://blogs.vmware.com/performance/2017/03/sql-server-performance-vmware-vsphere-6-5.html
i'm glad they included latency sensitivity in the testing. but the testing methodology limits the usefulness of the conclusion for me.
First a matter of system setup: the max configuration of vcpu count = physical core count seems to have been used.
While certainly better than vcpu count greater than core count (avoiding competition among vcpus for time on core) some core time for nonvcpu worlds and for the hypervisor is unavoidable. That means competition for time-on-core for some of that VM's vcpus.
To neutralize that effect, keeping vcpu count *lower* than core count is expected where consistent peak performance per core is desired.
That's a somewhat similar strategy to reserving vcpu0 in a SQL Server guest for the txlog writer, for example.
Performance per core is an important perspective for SQL Server & Oracle database, because license cost per physical core or vcpu is typically one of the largest individual line items in system cost (if not the largest).
Keeping vcpu count below core count is likely to be even more important for peak performance as cores per socket continues to rise.
Consider this passage from the recently updated VMware SQL Server Best Practices Guide.
http://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/solutions/sql-server-on-vmware-best-practices-guide.pdf

Here are some of the results included in the report.
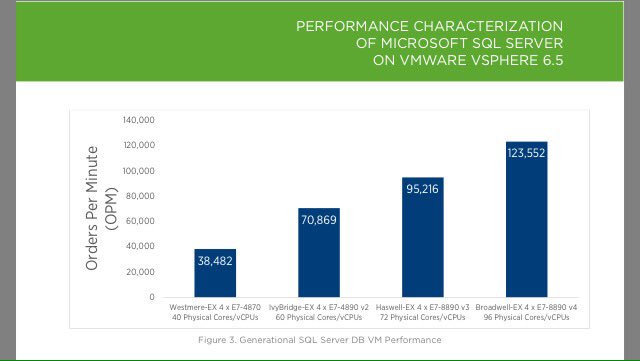
Let's break that down into Orders per Minute (OPM) per physical core.
E7-4870: 962 E7-8890v2: 1181 E7-8890v3: 1322 E7-8890v4: 1287
So there was a drop - a small one - in OPM per physical core between v3 and v4.
In addition to max transactions/sec scale achieved at vcpu = core count on each platform, I'd be interested in comparison for equal vcpu count across platforms.
40 vcpu vm comparison on E7-4870, E7-8890v2, E78890v3, E78890v4.
60 vcpu vm comparison on E7-8890v2, E7-8890v3, E7-8890v4.
72 vcpu vm comparison on E7-8890v3, E7-8890v4.
In fact, to allow room for the nonvcpu worlds, what I'd really like to see is:
36 vcpu vm comparison on E7-4870, E7-8890v2, E78890v3, E78890v4.
56 vcpu vm comparison on E7-8890v2, E7-8890v3, E7-8890v4.
68 vcpu vm comparison on E7-8890v3, E7-8890v4.
92 vcpu vm on E7-8890v4.
But, of course there's only so much time for testing, and only so much attention that can be given to reading test results. 😀 Max scale results are what the largest share of the audience would be interested in. Still - I want to share what makes testing - even thorough, careful testing like this - not directly applicable to some contexts. Mine in particular. 😀
In reality, right-sizing the vcpu count for a system involves more than reserving adequate remaining CPU resources for nonvcpu worlds and the hypervisor. Including more vcpu than is needed in a VM brings additional overhead into the vm - and the effect can be significant.
The first thing to consider is the NUMA node boundary. The reason NUMA exists is to allow platforms to continue to scale to increasing levels of compute and memory resources. NUMA gives preferential access from core to memory based on locality of the memory to the core. Cross the NUMA node boundary in a memory access, and memory bandwidth becomes a consideration as does the increase in memory latency. This is true as well for interprocess communication between threads on cores across the NUMA node boundary. If there's a 14 vcpu vm on a server with 2 twelve core per socket processors... that vm may well be better off with 12 vcpu within a single NUMA node.
Even within a single NUMA node, lowering the number of vcpu reduces scheduling overhead on the hypervisor. Using 10 vcpus within a NUMA node when 6 would suffice? Those extra vcpus are adding scheduling overhead.
Now lets consider Cost Threshold for Parallelism (CTFP). Here's what appears on page 14 of the test results.

SQL Server VM Performance with VMware vSphere 6.5
https://blogs.vmware.com/performance/2017/03/sql-server-performance-vmware-vsphere-6-5.html
i'm glad they included latency sensitivity in the testing. but the testing methodology limits the usefulness of the conclusion for me.
First a matter of system setup: the max configuration of vcpu count = physical core count seems to have been used.
While certainly better than vcpu count greater than core count (avoiding competition among vcpus for time on core) some core time for nonvcpu worlds and for the hypervisor is unavoidable. That means competition for time-on-core for some of that VM's vcpus.
To neutralize that effect, keeping vcpu count *lower* than core count is expected where consistent peak performance per core is desired.
That's a somewhat similar strategy to reserving vcpu0 in a SQL Server guest for the txlog writer, for example.
Performance per core is an important perspective for SQL Server & Oracle database, because license cost per physical core or vcpu is typically one of the largest individual line items in system cost (if not the largest).
Keeping vcpu count below core count is likely to be even more important for peak performance as cores per socket continues to rise.
Consider this passage from the recently updated VMware SQL Server Best Practices Guide.
http://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/solutions/sql-server-on-vmware-best-practices-guide.pdf
Here are some of the results included in the report.
Let's break that down into Orders per Minute (OPM) per physical core.
E7-4870: 962 E7-8890v2: 1181 E7-8890v3: 1322 E7-8890v4: 1287
So there was a drop - a small one - in OPM per physical core between v3 and v4.
In addition to max transactions/sec scale achieved at vcpu = core count on each platform, I'd be interested in comparison for equal vcpu count across platforms.
40 vcpu vm comparison on E7-4870, E7-8890v2, E78890v3, E78890v4.
60 vcpu vm comparison on E7-8890v2, E7-8890v3, E7-8890v4.
72 vcpu vm comparison on E7-8890v3, E7-8890v4.
In fact, to allow room for the nonvcpu worlds, what I'd really like to see is:
36 vcpu vm comparison on E7-4870, E7-8890v2, E78890v3, E78890v4.
56 vcpu vm comparison on E7-8890v2, E7-8890v3, E7-8890v4.
68 vcpu vm comparison on E7-8890v3, E7-8890v4.
92 vcpu vm on E7-8890v4.
But, of course there's only so much time for testing, and only so much attention that can be given to reading test results. 😀 Max scale results are what the largest share of the audience would be interested in. Still - I want to share what makes testing - even thorough, careful testing like this - not directly applicable to some contexts. Mine in particular. 😀
In reality, right-sizing the vcpu count for a system involves more than reserving adequate remaining CPU resources for nonvcpu worlds and the hypervisor. Including more vcpu than is needed in a VM brings additional overhead into the vm - and the effect can be significant.
The first thing to consider is the NUMA node boundary. The reason NUMA exists is to allow platforms to continue to scale to increasing levels of compute and memory resources. NUMA gives preferential access from core to memory based on locality of the memory to the core. Cross the NUMA node boundary in a memory access, and memory bandwidth becomes a consideration as does the increase in memory latency. This is true as well for interprocess communication between threads on cores across the NUMA node boundary. If there's a 14 vcpu vm on a server with 2 twelve core per socket processors... that vm may well be better off with 12 vcpu within a single NUMA node.
Even within a single NUMA node, lowering the number of vcpu reduces scheduling overhead on the hypervisor. Using 10 vcpus within a NUMA node when 6 would suffice? Those extra vcpus are adding scheduling overhead.
Now lets consider Cost Threshold for Parallelism (CTFP). Here's what appears on page 14 of the test results.
No comments:
Post a Comment