Third blog post in a quick series about potential trouble at the high AND low side of [\SQLServer:Buffer Manager\Target pages]. So far I've primarily talked about trouble on the low side of [Target pages], due to artificial restriction on the size of the database cache instance-wide, and an uneven expectation of [Free Memory] across the SQLOS memory nodes which can result in some SQLOS memory nodes having almost no database cache. This blog post is another example of the uneven demand for [Free Memory] across SQLOS memory nodes.
Here are the first two blog posts, in order, where I started discussing this topic.
https://sql-sasquatch.blogspot.com/2021/12/sqlserver-column-store-object-pool.html
The previous two posts have focused on December 1 on a particular system. That system is unusual in that it has 7 vNUMA nodes. That's a pretty surprising number, and it comes from the vNUMA configuration of that 80 vcpu vm not being aligned with physical resources beneath. That'll get straightened out sometime soon and it'll live the rest of its life as a 4x20 as soon as it does.
How much of the problem do I expect to go away once that system is a 4x20? A little. But it won't remove the problem entirely.
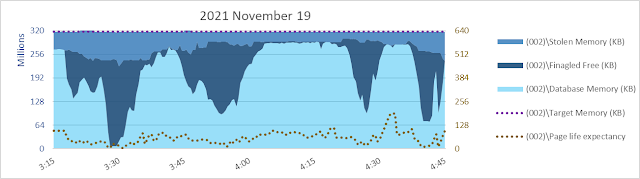
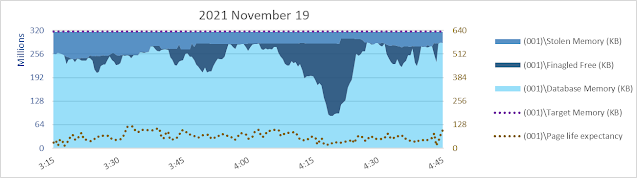
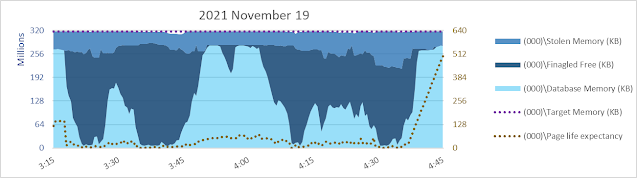
Let's look at a different system in this post - a 4x22, 88 vcpu system set up as good as I know how.
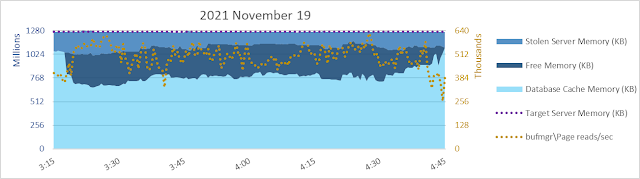
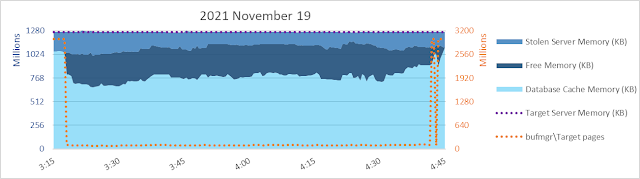
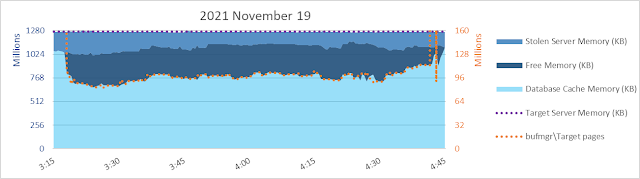
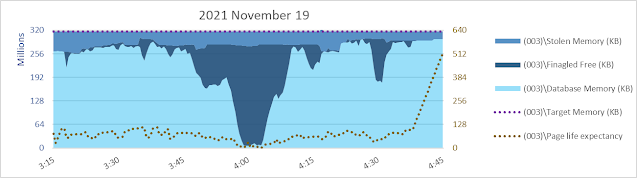
Well... yeah, there's something I don't necessarily like to see. Shortly after 3:15 am the database page read rate increases but database cache size decreases. Sometimes that happens, due to other memory commitments. There's only so much memory and if there's another need, database cache might hafta shrink even if it means more reads and more read waits. But in this case it isn't apparent there is a need for ~256 gb of SQLOS [Free Memory] to be maintained for over an hour. It looks like maybe something was anticipated, but never happened?
ReplyDelete"Wow, this was actually helpful. That section on workflows vs. projects is a total game-changer—it’s the kind of practical stuff you usually only learn the hard way on the job. Honestly, it's one of the easiest good knowledge of sql-tutorial lifecycle guides I’ve come across. Keep it up!"