http://msdn.microsoft.com/en-us/library/ms186865.aspx
Below is a graph from perfmon numbers collected in 15 second intervals. Don't laugh - it takes me forever to make graphs that look this cheesy :)
The primary vertical axis on the left is measured in seconds, for the average read latency (blue) and average write latency (red). Secondary vertical axis on the right is measured in megabytes per second, for the sum of read and write throughput.
The horizontal axis is a count of the 15 second intervals elapsed during the monitored activity.
This system has a simple recovery mode, multi-file database being backed up, using SQL Server backup compression. Eight equally sized LUNs each host a single MSSQL database row file. A single backup target LUN has lots and lots of backup target files. The read and write latencies, and the throughput graphed below are aggregates across those 8 database file and single backup target LUNs.

Migrating the system to a new server and new storage is a great time to recalibrate SQL Server backup. However, the backup was faster on the new system out of the box than on the older system - it seemed good enough so wasn't recalibrated. Maybe that's the way things would have stayed, too, if I hadn't started poking around.
No-one was troubled by 30 minutes elapsed time to backup a database that is over 1 TB in size - not even me. But, for an online backup, I'm averse to accepting high read latency. Read latency was often above 4 full seconds! I'm not a fan of such long waits. After graphing the activity as above, I was convinced the backup could be improved.
Back in the lab I convinced another performance engineer that this would be a worthwhile endeavor. (I get so many crazy ideas I have to show that some of them are worth testing time :) ) We didn't replicate the original system where the high latencies were observed - the goal was more basic, general backup tuning for the type of systems we normally work with. We used "dbcc traceon (3605, 3213, -1)" to store details about the backup execution in the SQL Server error log. The storage in our test system was presented from an EMC VNX, using 60 large form factor 15k disks in a virtual pool - so 12 RAID 5 4+1s. The backup source database was over 2 TB, with 24 equally sized row data files, each the sole resident of their own LUN (Windows mounted volumes rather than drive letters, just because we'd run out of letters). 12 of these LUNs were on each of the VNX storage controllers for balance. A single LUN contained all of the backup target files for each of the test executions. (From the start I believed that using two backup target LUNs, one on each storage processor, would be more beneficial due to balancing write cache needs - but I'll have to wait for another day soon to test that theory.)
When I think about optimizing online backups, there are three separate planes of optimization I have in mind:
1. Elapsed time. Everyone thinks of that one.
2. Read and write latency experienced by the SQL Server host. Its an online backup, right? Don't punish the users.
3. Latency effects on other tenants of the SAN. I put in lots of work to make systems "good neighbors".
So, what are the tunable knobs for turning? SQL Server T-SQL backup command allows overriding default behavior by supplying values for MAXTRANSFERSIZE and BUFFERCOUNT parameters. And the number of target files can easily be varied.
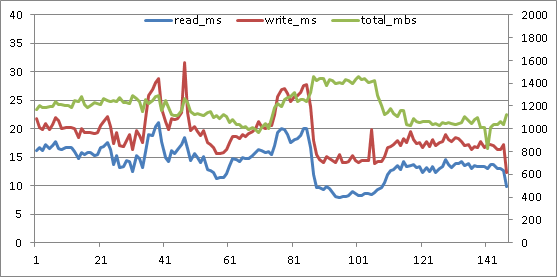
We started with MSSQL backup MAXTRANSFERSIZE at the default 1 mb. We were using perfmon to monitor at the Windows level, and Unisphere to monitor SAN activity on the VNX. Default MAXTRANSFERSIZE notwithstanding, the VNX said all write activity was coming in at 512kb. Hmm. Again... maybe most folks wouldn't complain. Between the reads and writes, more than 1 GB of data per second is being moved. And other than a singular peak, latency is kept well below 30 ms. Its actually much better than the original graph - far lower latency and higher throughput. But I'm not easily satisfied.
The 256 kb default max transfer size for AIX physical volumes had me thinking that the HBA on the SQL Server might have a 512 kb maximum transfer size - so that SQL Server's 1 mb backup IOs were being split into individual 512 kb operations by the HBA driver.
Should have been easy enough to investigate. But it wasn't. We had a QLogic HBA on the server. Thought maybe installing SanSurfer would allow us to see and set the HBA maximum transfer size. Not necessarily :) Its possible to have the HBA and driver installed and operating without error, and to install Sansurfer... but still not have the necessary components to check and set the maximum transfer size! Specifically, you'll need qlfc.exe or qlfcx64.exe to get or set the maximum transfer size.
You can find "Fibre Channel STOR Miniport 64-bit Driver for Windows 2008 (x64)" download packages here, check the readme package contents to make sure the qlfc executable you need is included.
http://driverdownloads.qlogic.com/QLogicDriverDownloads_UI/SearchProductPreviousRelease.aspx?ProductCategory=39&Product=1044&Os=173&ResourceCategory=Drivers&grid=1
My favorite resource for using qlfc from the command line:
http://adminhelpline.blogspot.com/2012_07_01_archive.html
After installing the component, I retrieved the maximum transfer size with this command:
qlfcx64.exe -tsize /fc
Sure enough. 512 kb default maximum transfer size. With driver version 9.1.8.28 or later, max transfer size can be set up to 2048 kb or 2 mb with this utility:
The change requires a reboot to become effective.
So on the test system, since the Windows volumes were based on Virtual Provisioning, the default write-aside was in place: writes larger than 1 mb would bypass SAN cache and writes 1 mb or less would go to write cache. Here's the test results: 4 target files, 1 mb SQL Server max transfer, 2 mb HBA max transfer.
qlfcx64.exe -tsize /fc /set 2048
Then we returned to testing. Its important to note that on the VNX, like the CLARiiON before it, there is a 'configurable' write-aside value: a write size threshold beyond which the write bypasses SAN cache. The write-aside is specified in 512 byte blocks. The default value is 2048, or 1 mb. For traditional LUNs, the write-aside can be set to a nondefault. However, "Caching and prefetching for Virtual Provisioning-based storage cannot be changed." page 16
http://www.emc.com/collateral/hardware/white-papers/h5773-clariion-best-practices-performance-availability-wp.pdf

So, increasing the HBA max transfer size to 2 mb and using the default 1 mb maximum transfer size for the SQL Server backup allows each read and write to not be split up by the HBA driver. And all of the writes go to write cache. (Although writing to SAN cache makes the backup operation faster overall and mutes the impact of the writes on reads, on some systems the backup writes may saturate write cache. Write cache saturation can cause performance degradation both for the source SQL Server instance and other tenants of the SAN. In such cases, it will be best to use a 2 mb or 4mb SQL Server maximum transfer size to bypass the write cache, and an HBA max transfer size equal or greater than the SQL Server transfer size.) Throughput has increased, and latency has dropped! Amazing, huh?
Write latency now peaks under 25 ms, and read latency stays under 15 ms for the duration of the backup. I think it can still get better. I'm looking to make throughput stay steady right around 1600 megabytes/second - about the maximum throughput the system will allow. Now that the HBA isn't chopping up reads and writes before passing them on... its time to increase the number of files again. Here's what happened at 6 files, default 1 mb SQL Server max transfer, 2 mb HBA max transfer.

Wow! That's the best yet! Throughput went up again, the read and write latencies inched up again, but the total elapsed time for the backup dropped again. I'll come back for another round of tuning in a while... this last round of testing, especially the two write latency spikes above 30 ms, makes me think that using two backup target LUNs, one on each controller in order to balance write cache usage, will be the best route to go. It'll be awhile before I get to play with this system again, though.
So... how is it that these changes could increase throughput AND decrease latency from the original? Here's a secret: don't fill your disk I/O queues. Don't fill them at the Windows volume level, don't fill the I/O queue for the HBA, don't fill the SAN port queue, don't fill the queue within the SAN for its internal LUN/logical device. When an IO queue is filled, throttling takes place. That just increases your IO wait time. If combining smaller sequential reads and writes into larger operations helps you get from an overflowing IO queue to a busy but sufficient IO queue... database users will notice the difference.
If you want to test this or other backup tuning strategies, take a look at this method for automating your testing/tuning.
http://sirsql.net/blog/2012/12/12/automated-backup-tuning
good job.
ReplyDelete