A support ticket concerning this behavior is open with Microsoft. SQL Server 2017 CU20 has not been evaluated for this behavior. Although no published fix included in CU20 appears to address this behavior, it's possible additional affects of the documented fixes address the behavior. Its also possible an undocumented CU20 fix addresses this behavior. However, as CU20 has never been brought up in the context of the support ticket, and - as can be seen at the end of this blog post - Microsoft has previously documented fixes to similar behavior, I currently believe this behavior is likely to exist in SQL Server 2017 CU20 as well as CU17, CU18, and CU19.
Let's start the story with a SQL Server 2017 CU17 service restart on December 20, 2019.
All of the graphs below unless otherwise noted are from perfmon, captured in 30 second increments.
It's a VMware VM, with Windows Server 2016 as the operating system. Global startup trace flags 4199 (optimizer hotfixes), 4139 (quickstats histogram amendments), 3226 (no errorlog messages for successful t-log backups). Nothing too surprising there.
This vm has 56 vcpu and 620 GB vRAM.
[Max Server Memory] is set to 590000 mb.
12/20/2019 11:03:24,spid8s,Unknown,SQL Server shutdown has been initiated
12/20/2019 11:03:24,spid8s,Unknown,SQL Trace was stopped due to server shutdown. Trace ID = '1'. This is an informational message only; no user action is required.
12/20/2019 11:03:25,Server,Unknown,Microsoft SQL Server 2017 (RTM-CU17) (KB4515579) - 14.0.3238.1 (X64) <nl/> Sep 13 2019 15:49:57 <nl/> Copyright (C) 2017 Microsoft Corporation<nl/> Enterprise Edition: Core-based Licensing (64-bit) on Windows Server 2016 Standard 10.0 <X64> (Build 14393: ) (Hypervisor)
12/20/2019 11:03:25,Server,Unknown,UTC adjustment: -6:00
12/20/2019 11:03:25,Server,Unknown,(c) Microsoft Corporation.
12/20/2019 11:03:25,Server,Unknown,All rights reserved.
12/20/2019 11:03:25,Server,Unknown,Server process ID is 12764.
12/20/2019 11:03:25,Server,Unknown,System Manufacturer: 'VMware<c/> Inc.'<c/> System Model: 'VMware Virtual Platform'.
12/20/2019 11:03:25,Server,Unknown,Authentication mode is MIXED.
12/20/2019 11:03:25,Server,Unknown,Logging SQL Server messages in file 'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\Log\ERRORLOG'.
12/20/2019 11:03:25,Server,Unknown,The service account is '***redacted***'. This is an informational message; no user action is required.
12/20/2019 11:03:25,Server,Unknown,Registry startup parameters: <nl/> -d C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\master.mdf<nl/> -e C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\Log\ERRORLOG<nl/> -l C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\mastlog.ldf<nl/> -T 4199<nl/> -T 4139<nl/> -T 3226
12/20/2019 11:03:25,Server,Unknown,Command Line Startup Parameters:<nl/> -s "MSSQLSERVER"
12/20/2019 11:03:25,Server,Unknown,SQL Server detected 28 sockets with 2 cores per socket and 2 logical processors per socket<c/> 56 total logical processors; using 56 logical processors based on SQL Server licensing. This is an informational message; no user action is required.
When [Max Server Memory] can be attained by SQL Server, [Target Server Memory] will be equal to [Max Server Memory]. If memory conditions external to SQL Server make [Max Server Memory] unattainable, [Target Server Memory] will be adjusted downward to an attainable value. As workload is placed on the system, [Total Server Memory] grows toward [Target Server Memory]. That's typical, expected behavior.
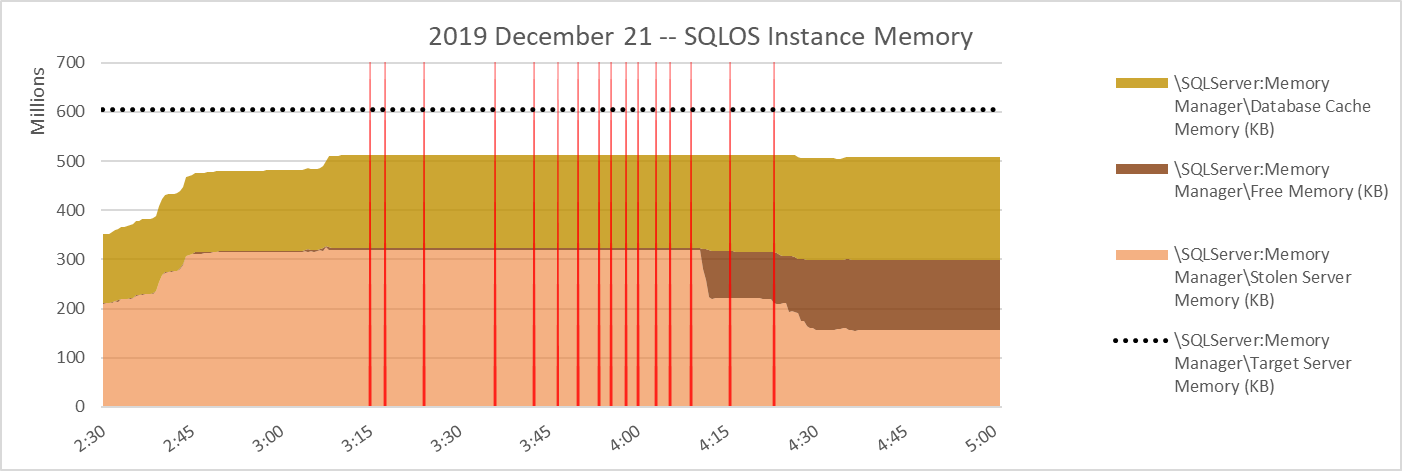
In this case, the story stays boring until after the following midnight. There wasn't enough workload to drive much growth of [Total Server Memory] until about 2:15 am, after which [Total Server Memory] grew fairly rapidly. [Total Server Memory] reached a plateau between 3:00 am and 3:15 am, and then stepped slightly down later. [Target Server Memory] was never attained. That's curious.
[Total Server Memory] is the sum of [Database Cache Memory], [Free Memory], and [Stolen Memory] for the instance. Here's a graph of those three memory categories over the same timeperiod.
It really is quite curious that [Total Server Memory] never reached [Target Server Memory] and in fact eventually backed *farther off* from [Target Server Memory]. If external factors made [Target Server Memory] unattainable, I expect [Target Server Memory] to be adjusted downward. But that didn't happen.
I'm a very curious guy, but I don't spend days worth of time creating and staring at graphs of the same short timeperiod simply out of curiosity. This morning timeperiod encompassed 16 SQL Server out-of-memory errors. I want to be able to diagnose them, and find out when the contributing behavior was introduced, in order to advise organizations that are planning SQL Server upgrades - or that fall prey to the type of OOMs experienced in this instance.
I'm going to tighten the timeframe for the remaining graphs to 2:30 am to 5:00 am, in order for the individual errors to be discernable on the graphs.
There are the 16 OOMs, each marked with a vertical red line in the graph below. Interestingly, they occur during the plateau of [Total Server Memory]. But... SQL Server is still a long way off from reaching [Target Server Memory]... why not just grow SQL Server's memory share?
As I mentioned before, if external memory conditions made [Target Server Memory] unattainable, I expect [Target Server Memory] to be lowered. That didn't happen, hinting that sufficient memory was still present for [Total Server Memory] to grow.
What does perfmon have to say about [Available Memory]? Does it corroborate my conclusion that SQL Server *could have* continued to grow [Total Server Memory]? Sure 'nuf. At the time of *all 16* of the OOMs, there was over 100GB of [Available Memory], nicely divided across the 2 vNUMA nodes.
Those familiar with my memory graphs on this blog and in my twitter activity as @sqL_handLe may note that I'm usually much more preoccupied with [Free & Zero Page List Memory] than with [Available Memory]. Depending on the memory consumers and activity on a VM, there may be considerable memory accounted as [Available Memory] which is not [Free & Zero Page List Memory]. If a memory allocation for a consumer must be zeroed before handed over, it's gotta come from [Free & Zero Page List Memory] (which I often affectionately call FZPL).
Thankfully in this case, FZPL is nearly all of [Available Memory] and is similarly well-divided between the vNUMA nodes.
So [Available Memory] and [Free & Zero Page List Memory] are plentiful and balanced between the two vNUMA nodes. Can we see how much of SQL Server [Total Server Memory] is on each of the SQLOS nodes? Yup. Meet my friend [Total Node Memory]. Equally balanced across the two SQLOS nodes.
In fact, the categories of [Database], [Stolen], and [Free] SQLOS memory can be tracked at SQLOS node level, too. Pretty nice balance on nodes 000 and 001.
Extracted from the SQL Server errorlog, here are the 16 OOMs from that night.
12/21/2019 03:15:27,spid83,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 03:17:43,spid79,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 8
12/21/2019 03:24:02,spid51,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 8
12/21/2019 03:36:37,spid73,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 03:42:54,spid89,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 03:46:54,spid55,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 03:50:36,spid57,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 03:53:56,spid73,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 03:55:57,spid73,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 03:58:28,spid73,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 04:00:39,spid52,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 04:03:14,spid70,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 16
12/21/2019 04:05:34,spid74,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
12/21/2019 04:09:26,spid70,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 24
12/21/2019 04:15:44,spid107,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 8
12/21/2019 04:23:14,spid94,Unknown,Failed to allocate BUFs: FAIL_BUFFER_ALLOCATION 1
So here's the summary of the story: 16 OOMs occurred in one night. The instance hadn't reached [Target Server Memory], and there doesn't seem to be a good reason for [Total Server Memory] to *not* have grown rather than incur an OOM. There was over 50GB of FZPL per vNUMA node, for goodness sake! Memory use seems to have been quite evenly divided between the vNUMA nodes.
For the last two OOMs, at 4:15 am and 4:23 am, there was even a large amount of [Free] SQLOS memory within [Total Server Memory]. And there was plenty of [Free] SQLOS memory on either of the two SQLOS nodes!! The possibility of SQLOS [Total] memory growth at the time of any of the 16 OOMs, and the additional presence of significant SQLOS [Free] memory on either SQLOS node during the last 2 OOMs fully convinces me that this is a bug. (Well, that and not having seen this type of behavior in any of the SQL Server 2016 or 2019 versions I've worked with.)
When the dust clears from this, I think a bug similar to this one from SQL Server 2017 cu10 will be found. I am upset at myself that in 5 months of staring down *this* behavior, I haven't been able to marshal the resources to get *this* bug properly identified so it can be corrected.
FIX: Out of memory error occurs even when there are many free pages in SQL Server
https://support.microsoft.com/en-us/help/4347088/fix-out-of-memory-error-when-there-are-free-pages-in-sql-server
The fix referenced above, kb4347088, is found in SQL Server 2017 cu10 and SQL Server 2016 sp2 cu3. The problem described in this blog post shares some similarities, and has been observed on SQL Server 2017 cu17, cu18, and cu19. As of 2020 April 16 this bug has not been identified and there is no fix imagined or planned.